
Large Language Models (LLMs) are at the forefront of Artificial Intelligence (AI), drawing attention for their massive scale, often made up of tens or hundreds of billions of parameters. Thanks to their capabilities in natural language understanding, all-rounder LLMs like ChatGPT or Claude excel in a range of tasks, including text summarization, translation, question answering, and even simple programming.
What defines a Large Language Model?
What makes LLMs special remains a bit of a mystery, but it’s thought that the sheer size of these models gives them the ability to do things that smaller models can’t. Therefore, the number of parameters in an LLM, which represents the amount of weights it learned during training, is taken as a significant index, given that this size directly influences the model’s learning capacity and complexity. Work by Google Research has demonstrated that if the model size increases, the model’s performance does not only improve across existing tasks but also reveals new competences, illustrated here:
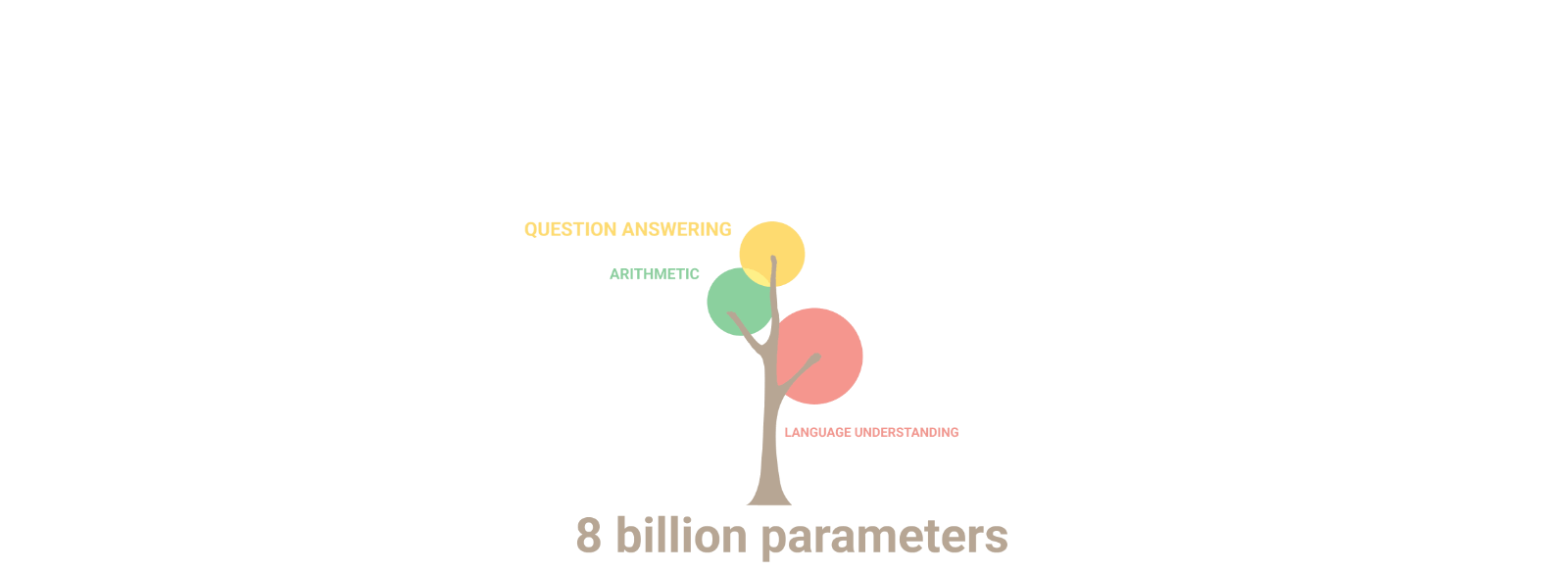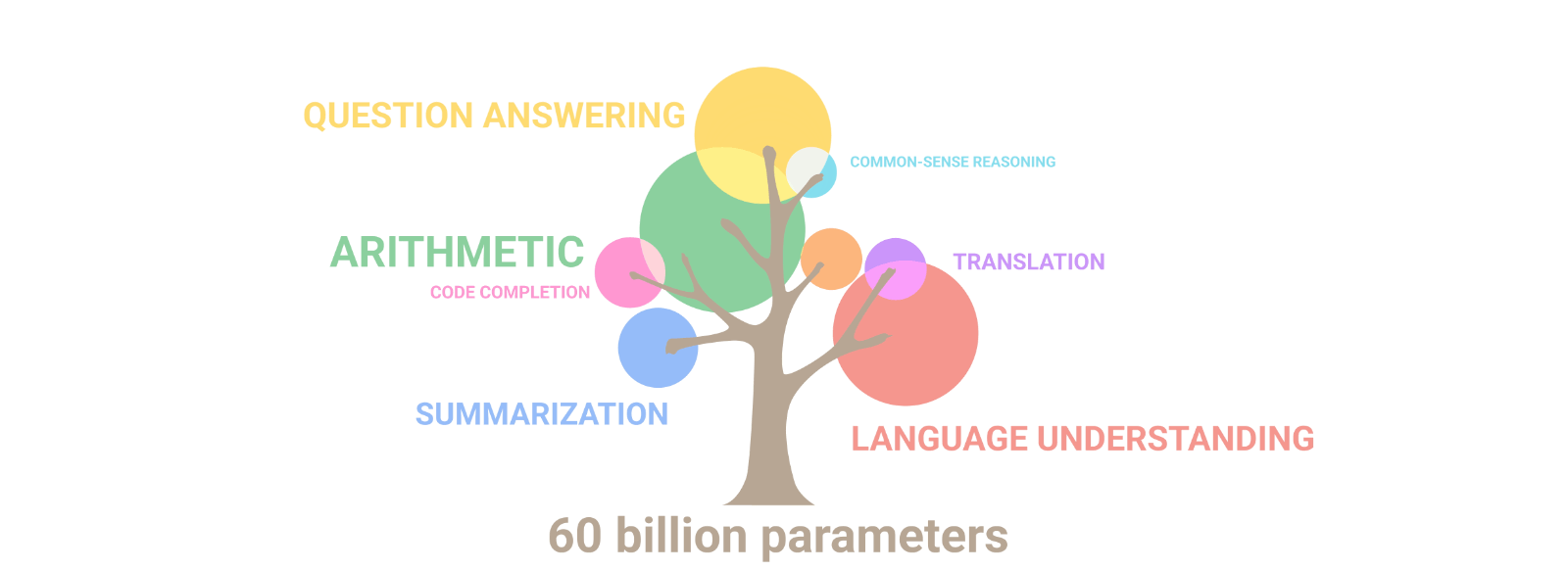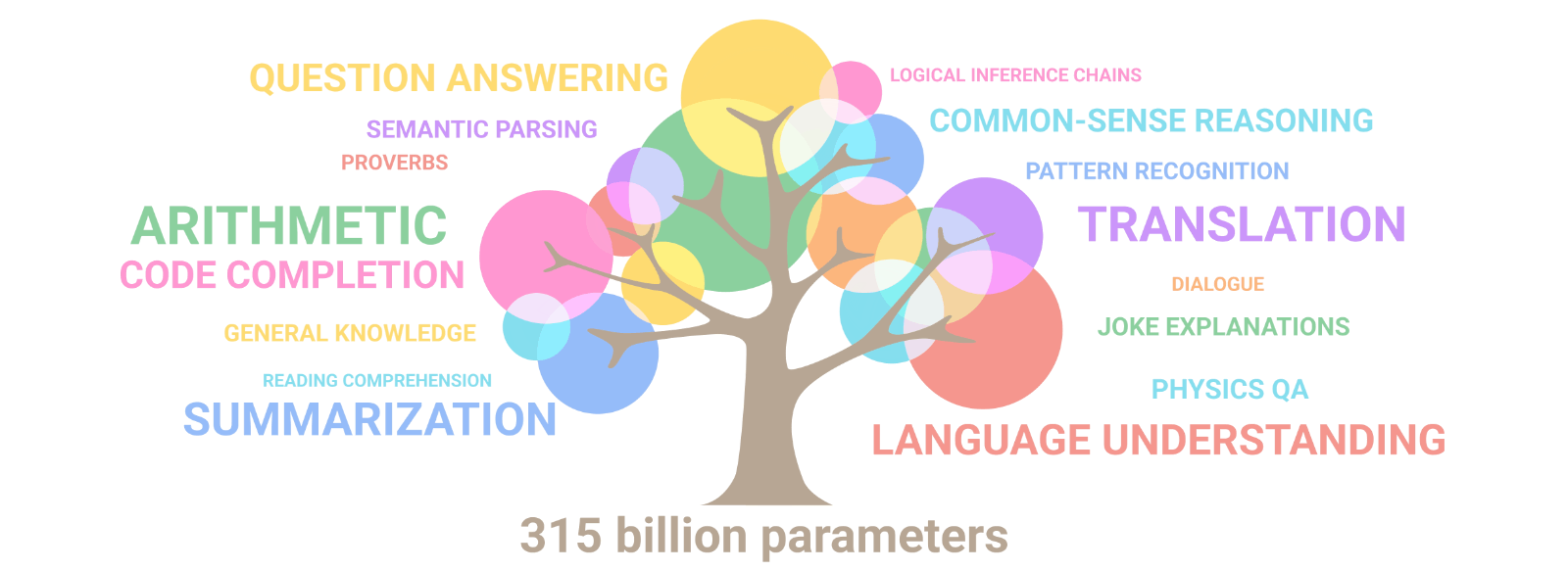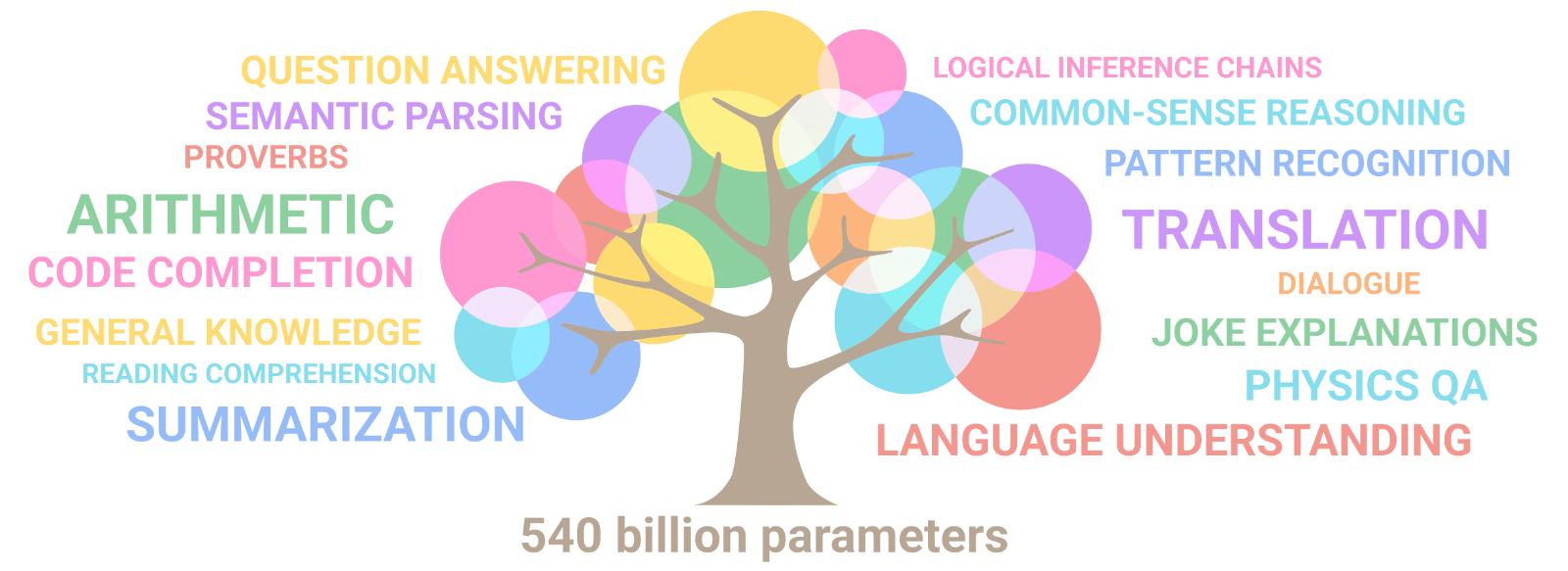
Another way to analyze LLMs is by looking at their computational complexity through a metric called floating-point operations (FLOPs), which tells us about the computer power they need and their potential energy consumption. You can check out this interactive graph, a preview given below, which illustrates the unbelievable, rapid evolution made in the past years but also the increasing impact in terms of carbon footprint during training: FLOPs estimated from the AI literature.
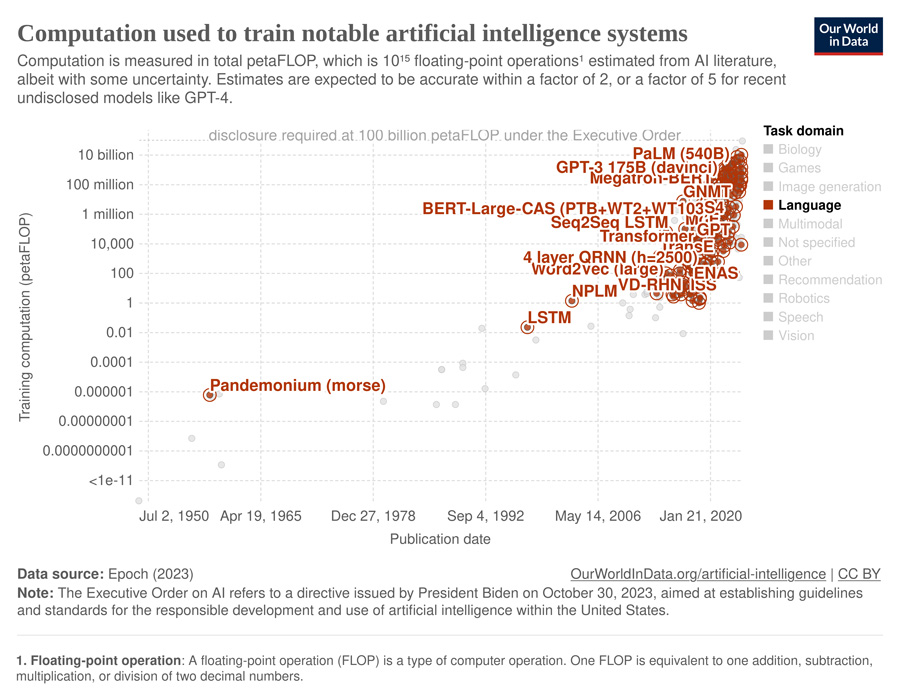
The growth of LLMs has been fast, leading to challenges in terms of the amount of computing power and memory they require. This is challenging for both academic research and practical usage, emphasizing the need for continuous exploration and optimization in the journey towards unleashing the full potential of LLMs for everyone.
Ranking Large Language Models: Leaderboards
In the field of natural language processing (NLP), a model leaderboard is a ranking system that evaluates and compares the performance of different LLMs on specific tasks or benchmarks. They provide a quantitative measure of how well selected models perform in specific tasks, such as language understanding, generation, translation, and more. Thus, open, standardized, and reproducible benchmarks hold immense value and contribute transparency to the understanding of model performance.
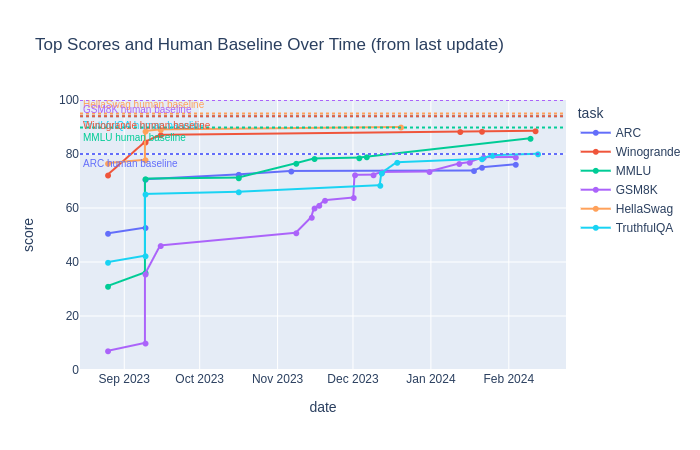
The performance of these models on various NLP tasks is normally compared to human performance, which is regarded as the gold standard in the field. As the Hugging Face Open LLM Leaderboard indicates (see also below), in the past months LLMs’ top scores have been progressively approaching the human set baselines (dotted).
The HELM (Holistic Evaluation of Language Models), maintained by Stanford’s Center for Research on Foundation Models, evaluates LLMs on a wide variety of open datasets and metrics. While this lite HELM version gives rise to the common assumption that bigger (in terms of parameters amount) is always better, “smaller” models like Mistral v0.1 (7B) actually exhibit surprising performance in various general-purpose tasks compared to models ten times their size.
A further view on LLM facts: unlike most leaderboards that focus solely on reporting model accuracy, HELM classic offers a comprehensive evaluation that provides insights into the model’s reliability through metrics like bias, efficiency, fairness, robustness, and toxicity for almost all the reported tasks (since Nov. 2022). Note that half of the models in this leaderboard are open source: 2023 was the year that unleashed the power and potential of Open Source LLMs!
Recent research has also focused on evaluating LLMs based on how well they follow instructions and answer to open-ended questions (e.g., Can you help me write a formal email to a potential business partner proposing a joint venture?), leading to new ways of understanding and measuring their capabilities. This is important for making sure that as LLMs are developed and used, they are getting better in a way that is meaningful and reliable. Check out HELM Instruct, a multidimensional evaluation framework, and the performance results of 4 instruction-following models (namely, GPT-3.5 turbo (0613), GPT-4 (0314), Anthropic Claude v1.3, and Cohere Command xlarge beta). This framework offers a standardized and objective approach to evaluate performance, and therefore represents a significant step forward in the field of evaluating and understanding LLMs capabilities.
Finally, evaluating LLMs is crucial when making improvements, like adding new features to a product. It’s important to not only add new capabilities but also to ensure that these changes make the overall product better, without causing any undesired side effects. This can be carried out manually or automatically through tests, and although it’s challenging due to the wide range of tasks and standards, it’s essential for continuous improvement.
LLM Deployment Dichotomy: Open-Access vs. Commercial
When integrating an LLM into your project, the choice between open-access and commercial options is pivotal. This decision influences not only the technical capabilities of your project but also its operational dynamics and strategic potential. Here’s a comprehensive analysis of key considerations to guide you through this critical decision-making process.
Ease of Deployment and Scalability
Commercial LLMs stand out for their smooth deployment into projects. Accessible via straightforward API calls, they simplify the development process considerably. Moreover, these models come with scalable infrastructures, making them ideal for multi-tenant projects like Software as a Service (SaaS) platforms. This scalability ensures that your project’s infrastructure can grow alongside your user base without the need for significant additional investments in backend capacity.
Quality, Availability, and Control
The quality and capabilities of commercial LLMs often rank among the best, driven by continuous investments in research and development. However, their availability and response can suffer during peak usage times, potentially degrading service quality. Additionally, there’s the risk of models being deprecated or discontinued, leaving projects in the lurch and without control over the underlying models used.
Fine-Tuning and Security Considerations
Fine-tuning is notably easier with commercial LLMs, which may offer dedicated support and resources for customization. However, this comes with potential privacy and security concerns regarding data shared with third-party providers. In contrast, open-access LLMs allow for local hosting, which can significantly enhance data security as it allows you to keep sensitive information within your controlled environment.
Cost Implications and Performance
Open-access LLMs present an economically viable alternative, especially for projects where the cost of local hosting offsets the recurring expenses associated with commercial API usage. It’s worth noting that, for certain tasks, open-access models available through platforms like Hugging Face may outperform their commercial counterparts, offering superior solutions without the associated costs.
Deployment Challenges and Task-Specific Performance
Deploying open-access LLMs, particularly in high-demand scenarios, requires substantial engineering resources. This includes not only the initial setup but also ongoing maintenance to ensure optimal performance and reliability. Moreover, instructing open-access LLMs to achieve performance levels comparable to commercial offerings can be challenging for some tasks, thus requiring additional development and training investment.
Hence, the choice between open-access and commercial LLMs hinges on careful considerations of your project’s specific needs, including performance requirements, budget constraints, and security concerns. While commercial models offer ease of use, scalability, and high-quality outputs, they come with potential risks related to availability, control, and privacy. On the other hand, open-access models provide greater control and security at the expense of additional resource investment. By weighing these factors, you can make an informed decision that aligns with your strategic objectives and operational capabilities.
You are not alone
Navigating the complex landscape of LLMs may appear overwhelming for those not intimately familiar with the field, due to the very diverse capacities of available models, their variety in dimensions, performance ranking, and the different advantages and drawbacks featured by open-access vs. commercial models.. You probably envisage that integrating this technology can significantly benefit your project, yet an optimal deployment of such resources on your own might take a considerable amount of time. A convenient way out is therefore resorting to a dedicated team of professionals with the needed expertise and understanding to adeptly manage every aspect of the process. At Process Talks, we are equipped to assist you in embarking on this endeavor. Feel free to contact us to start your journey into the realm of LLMs together.





