
In the fast-paced field of Artificial Intelligence (AI), the last year has witnessed an unprecedented surge in the use of Generative AI, particularly through the widespread adoption of Large Language Models (LLMs) for a myriad of tasks. From summarisation or text rewriting functions to more intricate jobs, LLMs have become the go-to solution for various challenges in the AI field.
To truly harness their power, however, there is often the need to customize and ground these models to meet specific requirements. Some techniques for doing so are prompting, fine-tuning and retrieval augmented generation (RAG). Prompting and fine-tuning can be seen as differing from RAG in that they involve teaching the model on the “how” (i.e., how to better perform a task), whereas RAG involves teaching the model on the “what” (what knowledge it must have in order to understand and answer on a domain). In this article, we’ll focus on the former two techniques, shedding light on how they can elevate your AI projects to new heights.
Prompting vs. Fine-tuning
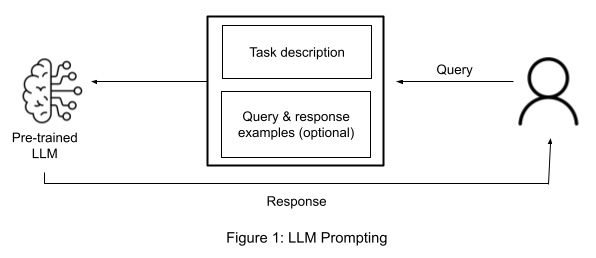
Prompting involves providing explicit instructions or examples to guide the language model’s output. Essentially, you’re instructing the model on how to perform a task or create specific content. It is optimal when the task requires a more generalized approach, and you want to guide the model’s behavior without delving into highly specific details.
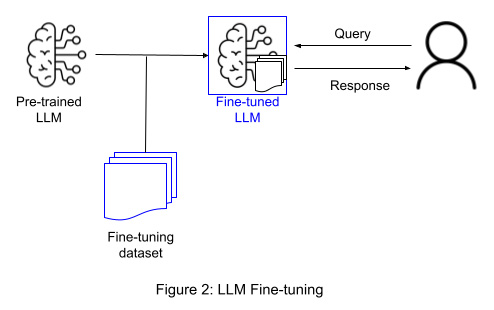
By contrast, fine-tuning is a more targeted approach where the model is trained on a particular dataset. It involves adapting a pre-trained model to a more specialized domain or set of tasks, and is the best option when the task at hand requires a deep understanding of domain knowledge or adaptation to a particular industry. For fine-tuning, large collections of data are needed to cover a relevant range of variety and therefore avoid model overfitting, i.e., when the model learns training data too well but fails on new unseen data due to being different from the learnt data.
The following table details key differences among the two approaches:
| Prompting | Fine-tuning |
| Scope | |
| Generally involves providing broad instructions and/or examples to guide the model’s behavior without significant modifications to its pre-existing knowledge. | Involves specific training on a larger dataset, adapting the model to a more specialized context or domain. |
| Flexibility | |
| Offers a more flexible and generalized approach, suitable for a wide range of tasks. | Provides a more tailored and domain-specific adaptation, sacrificing some generalizability for enhanced performance in a specific context. |
| Complexity | |
| Less complex as it typically involves working with the existing capabilities of the pre-trained model. | More complex, requiring the creation and curation of a dataset specific to the target task or domain. |
Target Application
We will explore the implications of using these two approaches taking as a use case a project on deploying a natural language interface that allows users to interact with their mobile app effortlessly, solely through voice commands. Note that this is not just about convenience; it’s a step towards inclusivity and accessibility for all.
A language interface of this sort includes, broadly speaking, a speech-to-text tool and a Natural Language Understanding (NLU) component. That NLU component is the magic that interprets user intentions and translates them into a tightly structured representation, ready for execution by the app backend. But how can that be deployed?
Unlocking the Power of LLMs
Now, here’s where the real magic happens. To make our NLU component intelligent and adaptable, we turn to LLMs. These sophisticated models, when grounded to the specificities of our task, can transform the way users interact with their mobile apps. This involves a multi-faceted approach through several steps. As illustrated in the following figure, these are: task analysis, data resources creation and finally, model deployment. We’ll leave the latter step for a coming post (so, stay tuned!).
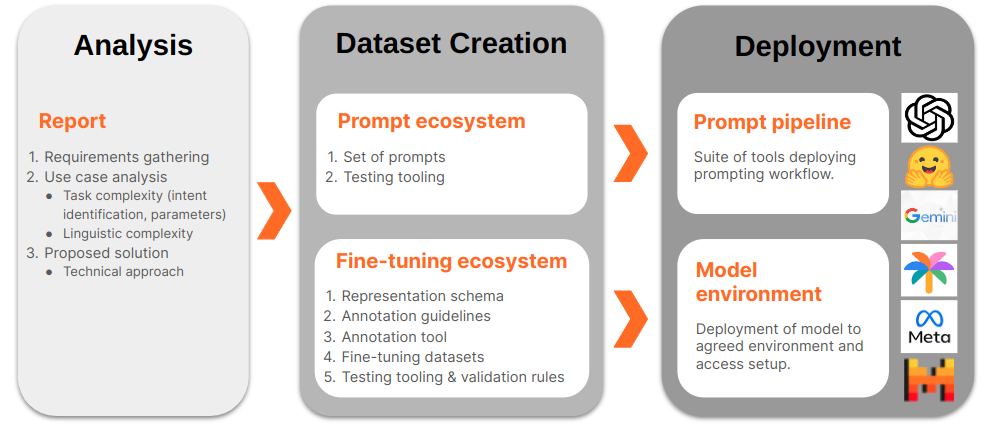
Step 1. Target Task Analysis
Before diving into the model grounding process, a comprehensive analysis of your target task is imperative. More precisely, you need to understand the linguistic and domain complexities that it entails.
Linguistic Complexity: Consider what are the languages required for your project. Are they languages with large digital coverage and so you can expect them to be already widely represented in the source LLM? Are they linguistically similar, allowing for shared data usage during model grounding?
Domain Complexity: Delve into the intricacies of your task. How complex is the data involved for the functionalities you need to cover? And how can we structure them in a way that the app backend can seamlessly execute? For our accessibility interface example, this would involve identifying user intents, parameters and anything related to different types of user commands. Considerations that would be relevant here are: is it enough to set a single intent for, e.g., calendarizing an event, or by the contrary we rather must differentiate depending on whether we invite other people? What are the elements to be distinguished on an event calendarizing intent (e.g., organizer, attendees, date and time, duration, location, title, etc.)?
This analysis lays the foundation for effective customization, guiding your choice between prompting and fine-tuning, or towards a hybrid approach that combines both.
Take our use case at hand. Let’s consider that there are two different functionalities that we want to implement. Firstly, a step that given a user input that includes in fact several commands, such as:
Reply to Maria’s last whatsapp message with a thumbs up, forward it to the team chat and then start playing the video I received from Pau.
is able to identify and separate them into single intents, e.g., very schematically: 1. reply to message; 2. forward it; 3. play video. Secondly, a step whereby user commands, which can be of very different types, are interpreted and converted into structured representations that can be consumed by the backend.
The technological solution to adopt here is quite clear. While the first functionality can be trained simply with prompting, the second involves a degree of complexity that can only be hanled by resorting to fine-tuning (in the following section we will justify why in some more detail). So for our NLU component, we opt for a hybrid approach that combines both techniques.
Step 2. Data Development
With insights from our task analysis, the next step is developing the resources required to ground the model effectively.
Prompt Ecosystem
Prompting is a trial-and-error process where you craft a set of input instructions or queries designed to elicit the desired response from the model. For our specific use case, the prompt should instruct the model that, given a user command, it must return a structure representing the several semantic elements of the sentence, and then add a few examples of what is expected. Figure 5 provides a very simple mock-up example for user commands on calendarizing events.
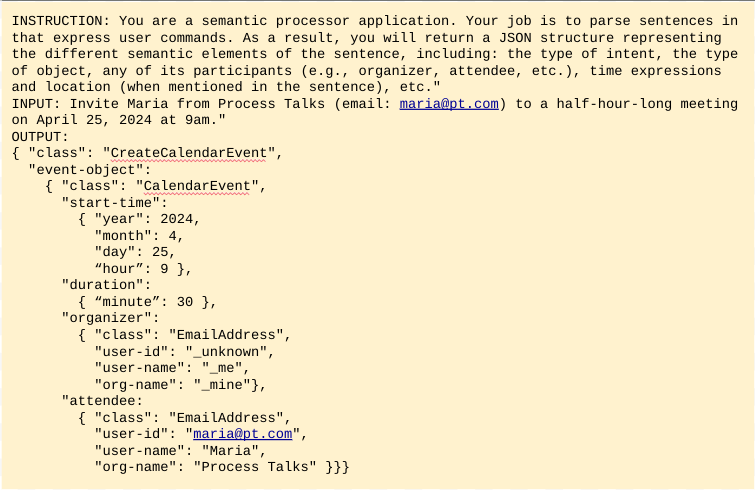
The development environment for prompt engineering is therefore quite straightforward: a suite of scripts for prompt engineering iteration and progress testing, which is at the hand of many companies including those with limited technical resources.
As already mentioned, however, prompting is not indicated for tasks with some significant level of complexity. When requested to generate JSON structure, as in our example above, it is very likely that the result does not validate against the expected schema. The model can act creatively in undesired ways, introducing new attributes, reshaping the hierarchy or missing required values. Therefore, prompting is not the best option for a task such as the one just illustrated, although we already saw that it can be used for simpler ones, like determining the several intents that may be passed together in a single command.
Fine-tuning Data Ecosystem
Technical requirements are a bit more demanding for fine-tuning, which is used for grounding LLMs on complex use cases and therefore needs much more sophisticated data. For our NLU interface, this corresponds to datasets of sentences expressing possible user commands accompanied by their annotations, i.e., their structured representations. Such annotations must satisfy a degree of quality and consistency to ensure the least amount of noise when training, a fact that imposes human involvement through the whole data creation process.
Key elements for reaching the degrees of needed quality and consistency are:
- A data representation schema systematizing user intents and their parameters into a structured format. This is done always hand in hand with the customer or user – here, the owner of the backend component that will consume the resulting representations.
For example, the schema for the intent used for adding an event to our calendar app would define the parameters relevant for that event (Figure 6): start-time, duration, location, organizer, attendees, etc. In its turn, each of those elements would be defined with a further schema at the needed level of detail, e.g., attributes organizer and attendees in Figure 6 refer to the user schema, which sets fields for name, email address, company, etc. (Figure 7).


- A set of annotation guidelines so that the human annotators align as much as possible among them, ensuring maximum consistency of the resulting fine-tuned model. This is critical to ensure maximum coherence among the different annotators and thus avoid noisy data. This includes from strongly linguistically based indications, such the following, giving instructions on when to set the user as the event organizer:

to more general ones:

- An annotation tool supporting the annotator’s effort by semi-automatizing some functions and which ideally has mechanisms for guaranteeing data consistency and soundness. At Process Talks we count on a proprietary tool called WILMA, which, among other functionalities, validates the data by means of a set of soundness rules designed for that. For instance, the following one requires that in intents on setting calendar events, the event object be of a specific class (e.g., a Teams user, an email address, etc.)

In summary, fine-tuning data generation demands a complex ecosystem (Figure 11). Key components there are, firstly, the interaction with the client, which is the essential ingredient to define the schema at the base of the fine-tuning datasets; secondly, a good annotation tool (such as WILMA) that ensures a data creation process as fast and smooth as possible and, finally, the intervention of expert annotators at different points in the process, which is crucial to guarantee a maximum level of data quality.

Conclusion
Customizing LLMs can be a daunting task, but with the right guidance, the possibilities are limitless. At Process Talks, we specialize in LLM grounding, offering tailored solutions to make your AI dreams a reality. Contact us today to explore how we can elevate your projects to new heights through the power of customization and innovation.





