
Los modelos masivos de lenguaje (MML) están al frente del desarrollo más reciente en inteligencia artificial (IA). Entrenados con decenas, incluso cientos, de miles de millones de parámetros, su escala formidable los dota de una gran capacidad para tareas complejas de comprensión del lenguaje natural. Modelos versátiles como ChatGPT o Claude sobresalen en un amplio abanico de funciones, como por ejemplo el resumen de texto, la traducción, la respuesta a preguntas o incluso tareas sencillas de programación.
¿Qué define un modelo masivo de lenguaje?
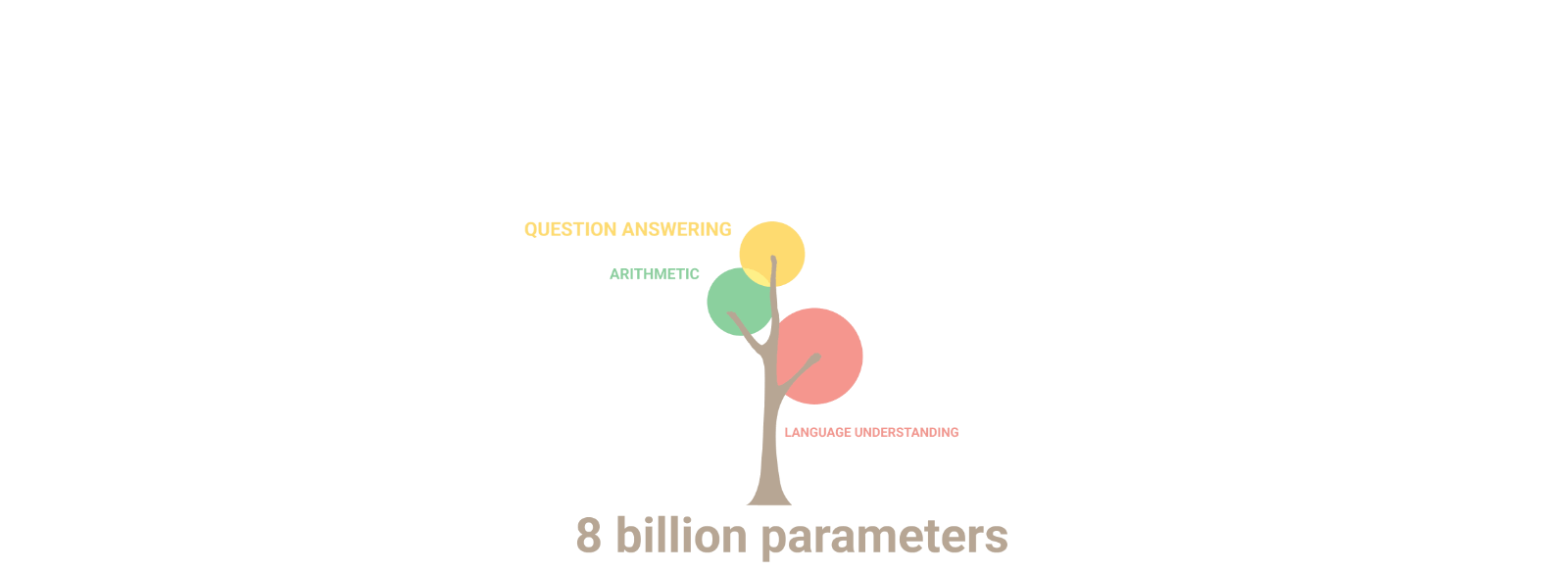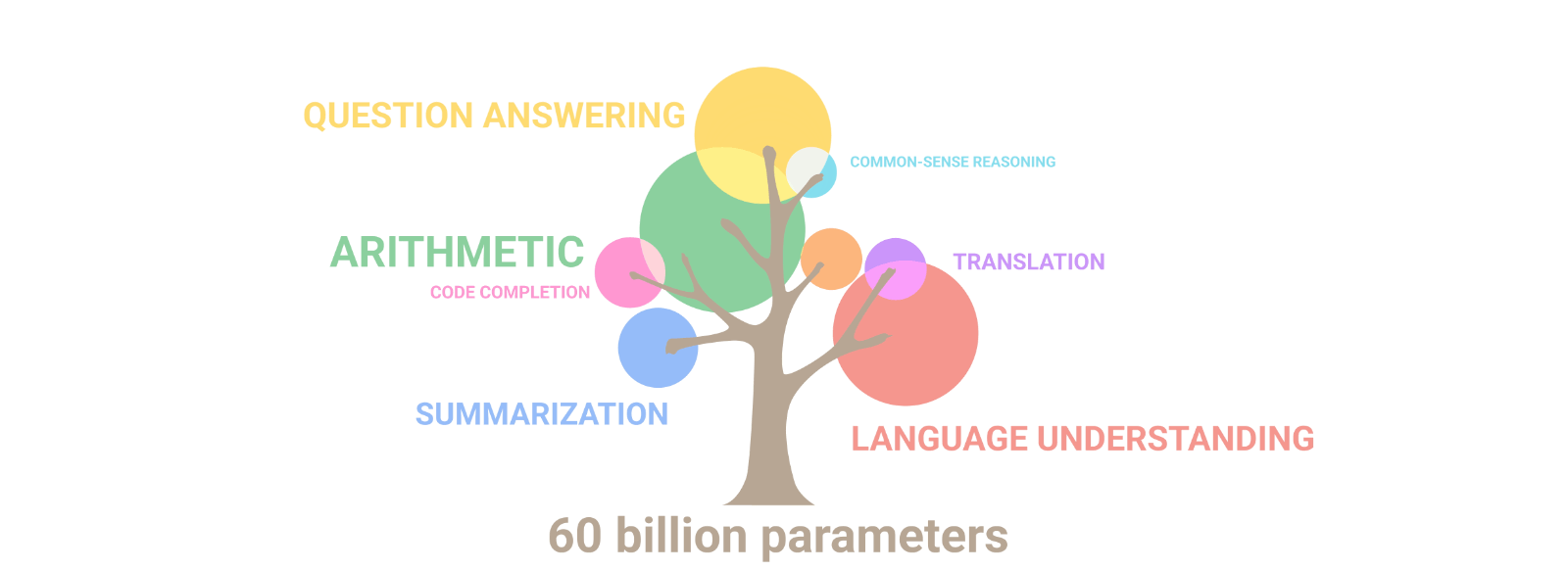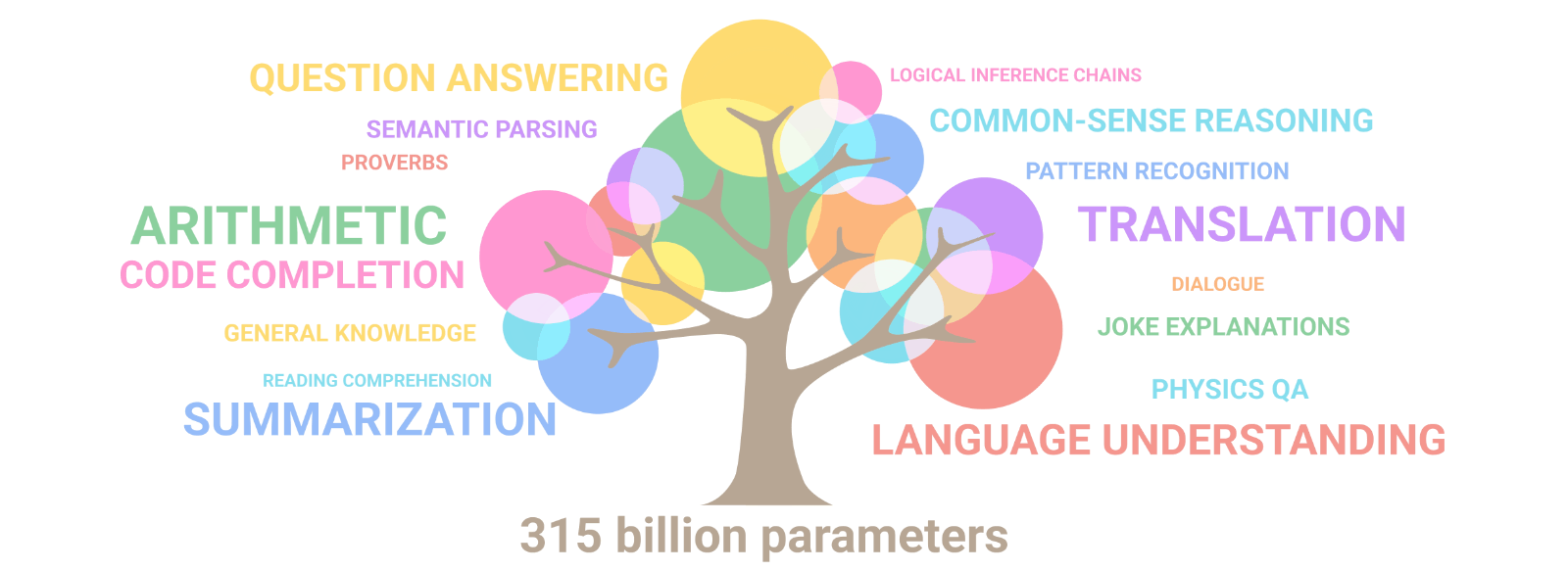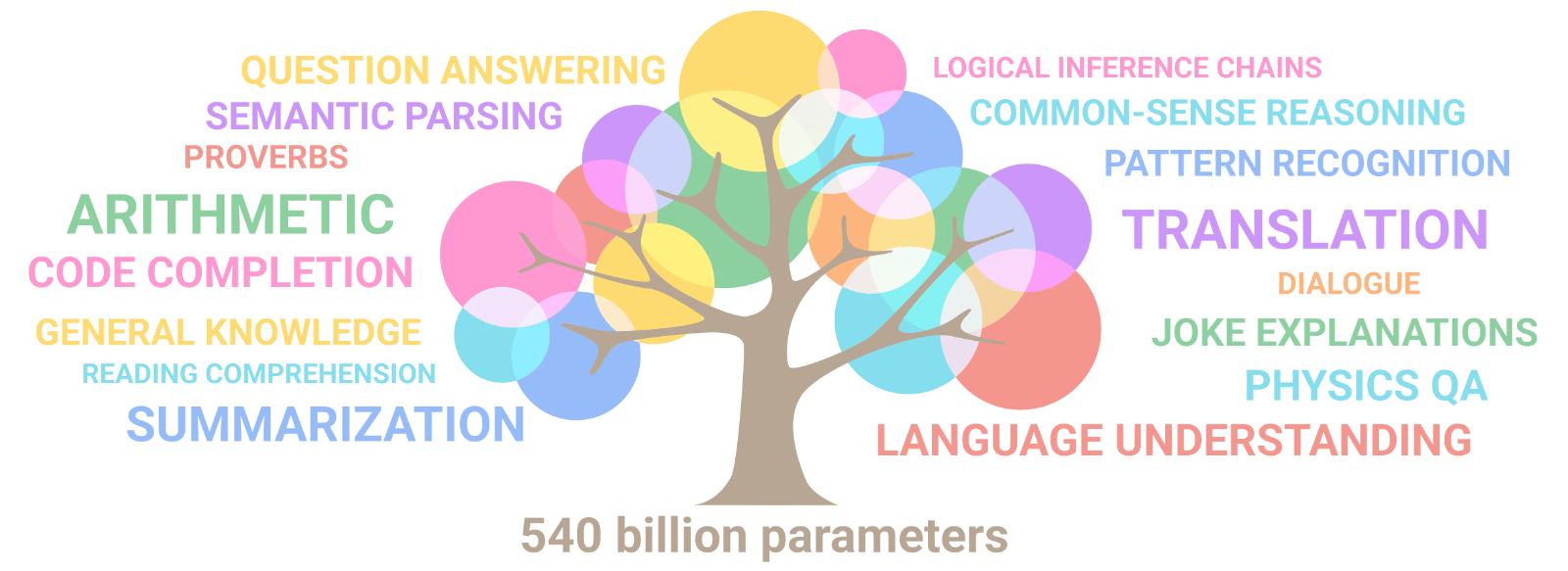
Lo que hace tan aptos y capaces estos MMLs es un poco un misterio todavía, pero se asume que es precisamente su dimensión lo que les da la capacidad de resolver tareas en las que modelos más pequeños se estrellan. Por tanto, el número de parámetros de un MML, que representa la cantidad de pesos aprendidos durante su entrenamiento, se toma como un índice significativo del modelo, dado que este tamaño influye directamente en su complejidad y capacidad de aprendizaje. Investigadores de Google Research han demostrado que cuando el tamaño del modelo aumenta, su rendimiento no sólo mejora en tareas ya conocidas sino que también manifiesta nuevas competencias, tal y como se ilustra en la siguiente figura:
Otra forma de analizar los MMLs es examinando su complejidad computacional mediante la métrica conocida como operaciones de coma flotante (en inglés, floating-point operations, FLOP), que nos informa sobre la potencia de computación que necesitan y su consumo potencial de energía. Puede verlo en este gráfico interactivo, mostrado también a continuación. Ilustra la increíble y rápida evolución de los últimos años, pero también el impacto creciente en términos de huella de carbono que tienen los modelos durante la fase de entrenamiento.
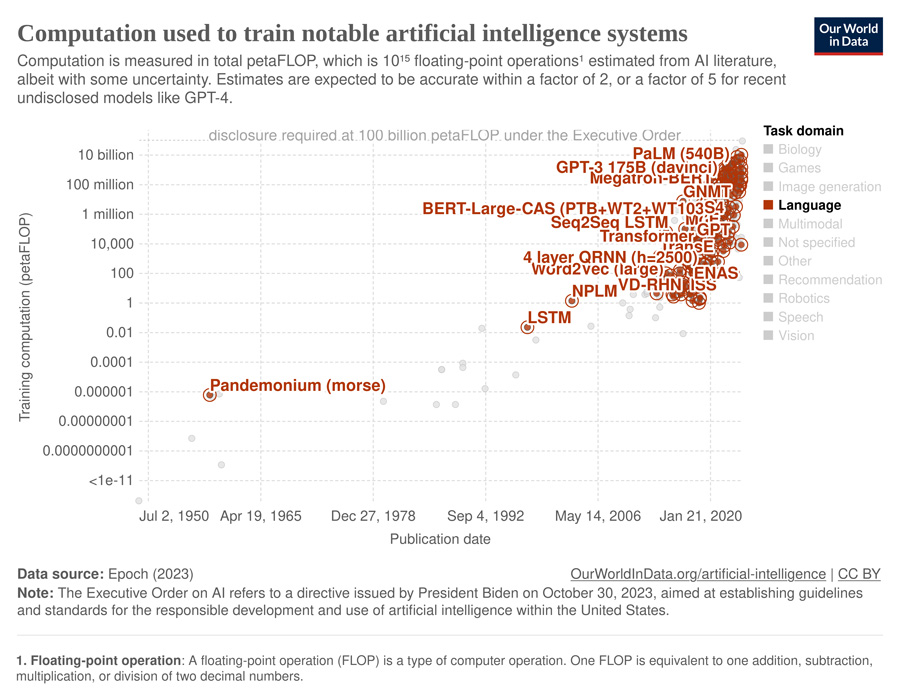
El crecimiento de los MML es muy rápido y comporta retos respecto a la cantidad de memoria y potencia de computación. Esto es un desafío importante tanto para la investigación académica como para el uso práctico de estos recursos, y pone por tanto el acento en la necesidad de innovación y optimización continua para poder poner a disposición de todos el potencial y las capacidades de los MMLs.
Clasificación de MML
En el ámbito del procesamiento del lenguaje natural (PLN), se utilizan tablas de clasificación (conocidas en inglés como leaderboards) para evaluar y comparar el rendimiento de los diferentes MMLs en base a tareas o marcadores específicos. Proporcionan una medida cuantitativa del rendimiento de los modelos en determinadas tareas, como la comprensión textual, la generación de texto o la traducción, entre otras. Estas tablas ofrecen puntos de referencia consensuados que se asumen como estándares, y tienen un valor inmenso porque ayudan a comprender la capacidad de los distintos modelos.
El rendimiento de los MMLs en diversas tareas de PLN se compara normalmente con el rendimiento humano, que se toma como el estándar de oro. Tal y como se indica en la tabla de clasificación de los MML de acceso abierto del Hugging Face, en los últimos meses las puntuaciones máximas de rendimiento de los MMLs se han ido acercando progresivamente al nivel de rendimiento humano (marcado con puntos en la siguiente figura):
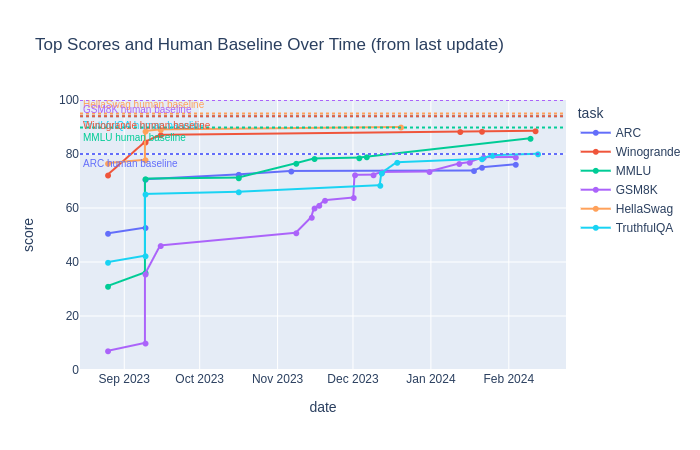
Más datos: HELM (siglas en inglés del marco de evaluación holística de modelos de lenguaje, desarrollado por el Center for Research on Foundation Models de la Universidad de Stanford), evalúa los MMLs en base a una gran variedad de conjuntos de datos y métricas. Aunque la versión Lite de HELM parece sugerir que cuanto mayor es el modelo (en términos de cantidad de parámetros) mejor, modelos de tamaño “más pequeño”, como Mistral v0.1 (7B), han demostrado un rendimiento sorprendente en diversas tareas de carácter genérico, en comparación con modelos que son diez veces mayores.
Y más aún: a diferencia de la mayoría de tablas de clasificación, que se centran únicamente en la métrica de precisión, la tabla HELM classic ofrece una evaluación completa, aportando también información sobre la fiabilidad de los modelos con métricas como el sesgo, la eficiencia, la equidad, la robustez y la toxicidad para casi todas las tareas contempladas en el análisis (desde noviembre de 2022 ). La mitad de los modelos en esta clasificación son de código abierto. Y es que el 2023 fue el año que el potencial de los MMLs de código abierto hizo finalmente eclosión.
También hay investigaciones recientes que han evaluado diferentes MMLs en base a lo bien que siguen instrucciones y son capaces de responder a preguntas abiertas (p. ej., ¿Puedes ayudarme a escribir un correo electrónico formal dirigido a un posible socio comercial para proponerle una empresa conjunta?), generando pues nuevas maneras de entender y medir sus capacidades. Todas estas modalidades de evaluación son básicas para asegurar que a medida que los MMLs se desarrollan y utilizan, mejoran de forma significativa y fiable. Echa un vistazo a HELM Instruct, un marco de evaluación multidimensional, y los resultados de rendimiento que muestra para 4 modelos en cuanto al seguimiento de instrucciones (GPT-3.5 turbo 0613, GPT-4 0314, Anthropic Claude v1.3 y Cohere Command xlarge beta). Este marco presenta un enfoque estandarizado y objetivo para evaluar el rendimiento de los MMLs y por tanto representa un paso importante para entender sus capacidades.
Por último, evaluar los MMLs es crucial a la hora de adaptarlos a tareas más específicas; lo que técnicamente se conoce como “aterrizar el modelo” (del inglés grounding). Es necesario aterrizar un MML cuando se quiere utilizar para añadir una nueva funcionalidad a un producto o aplicación determinada, como por ejemplo una interfaz que permita al usuario interaccionar simplemente hablando. No sólo es importante capacitar al modelo para la nueva tarea, sino que también hay que asegurar que esto mejora el producto en general y no causa ningún efecto secundario no deseado. Esta evaluación se puede realizar manualmente o bien de forma automática. Aunque es un reto debido al amplio abanico de tareas y estándares, es un paso esencial para la mejora continua del proyecto.
Dicotomía en el despliegue de MMLs: Modelos de acceso abierto o comerciales?
Cuando se integra un MML en un proyecto, la elección entre opciones de acceso abierto o comerciales es crítica. Esta decisión influirá no sólo en las capacidades técnicas del producto final, sino también en su dinámica operativa y su potencial estratégico. Ofrecemos a continuación un análisis exhaustivo de las consideraciones clave que deben guiar la decisión.
Facilidad de despliegue y escalabilidad
Los MMLs comerciales destacan porque permiten un despliegue fácil y fluido dentro de cualquier proyecto. Son accesibles mediante llamadas sencillas a través de interfaces de programación de aplicaciones (o APIs, en inglés), y por tanto simplifican considerablemente el proceso de desarrollo. Además, estos modelos incluyen infraestructuras escalables, lo que les hace ideales para proyectos que necesitan alojamiento múltiple (o multi-host), como las plataformas Software as a Sevice (SaaS). Esta escalabilidad garantiza que la infraestructura de un proyecto pueda crecer en paralelo al incremento de su base de usuarios, sin necesidad de inversiones adicionales importantes en el componente del backend.
Calidad, disponibilidad y control
Los MMLs comerciales suelen ser de mayor calidad y ofrecer unas capacidades más altas, ya que reciben el soporte de inversión continua en investigación y desarrollo. Sin embargo, su disponibilidad y capacidad de respuesta puede quedar resentida durante las horas punta de uso, lo que puede degradar su calidad del servicio. Además, existe el riesgo de que los modelos queden obsoletos o se retiren del mercado por parte de la empresa que los comercializa, y esto no sólo quita capacidad de control sobre estos modelos a los proyectos que los utilizan, sino que hasta puede dejarlos a la estacada.
Fine-tuning y seguridad
El proceso fine-tuning (o afinamiento) del modelo es notablemente más fácil utilizando MMLs comerciales porque suelen ofrecer recursos de soporte para esta tarea. Sin embargo, hacer fine-tuning sobre modelos comerciales puede acarrear problemas de privacidad y seguridad en cuanto a datos de terceros. En cambio, los MMLs de acceso abierto permiten alojamiento local, lo que mejora significativamente la seguridad de los datos al mantener la información confidencial dentro del entorno estrictamente controlado del proyecto.
Rendimiento y compra
Los MMLs de acceso abierto constituyen una alternativa económicamente viable, especialmente para proyectos en los que el coste del alojamiento local compensa los gastos recurrentes asociados al uso de la API de un modelo comercial. Vale la pena señalar que de hecho, para determinadas tareas, los modelos de acceso abierto disponibles a través de plataformas como Hugging Face pueden superar en rendimiento sus homólogos comerciales, ofreciendo por tanto soluciones superiores sin los costes asociados.
Retos de despliegue y rendimiento específico
El despliegue de MMLs de acceso abierto, especialmente en escenarios de alta demanda, exige recursos de ingeniería sustanciales. Esto incluye no sólo la configuración inicial, sino también un mantenimiento continuo que garantice un rendimiento y fiabilidad óptimos. Además, instruir los MMLs de acceso abierto para que lleguen a niveles de rendimiento comparables a los de los modelos comerciales puede ser un reto para ciertas tareas, por lo que es necesario una inversión adicional para aterrizar el modelo, por ejemplo haciendo fine-tuning.
Por tanto, la elección entre modelos de acceso abierto o comerciales debe hacerse considerando atentamente las especificidades de cada proyecto, incluyendo aspectos como los requisitos de rendimiento, limitaciones presupuestarias y problemas potenciales de seguridad. Aunque los modelos comerciales ofrecen una mayor facilidad de uso, capacidad de escalabilidad y resultados de alta calidad, presentan sin embargo riesgos relacionados con la disponibilidad, la autonomía y capacidad de control, y la privacidad de los datos. Por el contrario, los modelos de acceso abierto proporcionan un mayor control y seguridad a expensas de una inversión adicional en recursos.
Es sopesando todos estos factores que podréis tomar una decisión informada que se alinee con los objetivos estratégicos y las capacidades operativas de vuestro proyecto.
No estás solo
Navegar por el complejo paisaje de los MMLs puede parecer abrumador para quien no esté íntimamente familiarizado con el campo, dada las capacidades tan diversas de los modelos disponibles, su variedad de dimensiones, las diferencias de rendimiento y la serie de ventajas e inconvenientes que presentan los modelos de acceso abierto y los comerciales. Muy seguramente consideres que integrar esta tecnología en tu proyecto puede beneficiarlo significativamente, pero desplegar estos recursos por tu cuenta de forma óptima puede comportar una cantidad considerable de tiempo y recursos. Una solución conveniente a esta situación es acudir a un equipo dedicado de profesionales con la experiencia necesaria para gestionar con habilidad todos los aspectos del proceso.
En Process Talks tenemos el equipo que te puede ayudar en ese esfuerzo. Contacta con nosotros y te acompañaremos en el viaje por el nuevo reino de los MMLs.





