
El campo de la Inteligencia Artificial (IA) ha sido testigo este último año de un aumento sin precedentes en el uso de la IA generativa gracias a la adopción generalizada de modelos masivos de lenguaje (MML) para una infinidad de tareas. Desde funciones de resumen automático o reescritura de texto hasta tareas más complejas, los MML se han convertido en la solución ideal para retos muy diversos.
Sin embargo, para aprovechar realmente todo su poder, a menudo es necesario lo que técnicamente se conoce como “aterrizar” estos modelos; es decir, personalizarlos para que satisfagan los requisitos específicos de cada caso. Algunas técnicas para hacerlo son las que se conocen con los términos ingleses de prompting, fine-tuning y retrieval augmented generation (RAG). Las técnicas de prompting y fine-tuning difieren de RAG porque implican instruir el modelo en el «cómo» (es decir, en cómo realizar mejor una tarea), mientras que RAG le instruye en el «qué» (qué debe saber para entender y resolver cuestiones sobre un dominio determinado). En este artículo, nos centraremos en las dos primeras técnicas, explicando cómo las podéis incorporar en vuestros proyectos para elevarlos a niveles superiores de calidad, rendimiento y usabilidad.
Prompting vs.fine-tuning
El prompting consiste en guiar el comportamiento del modelo proporcionándole instrucciones (posiblemente acompañadas de ejemplos) que indican el tipo de resultado que se espera. Es ideal cuando la tarea a realizar permite una aproximación general y no hay necesidad de profundizar en detalles demasiado específicos o técnicos.
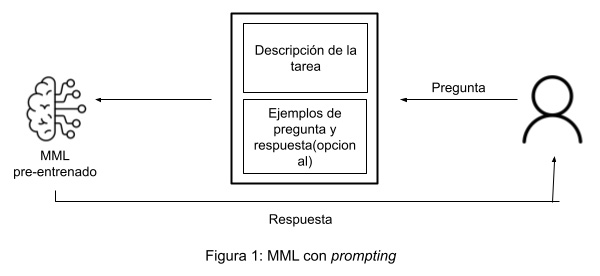
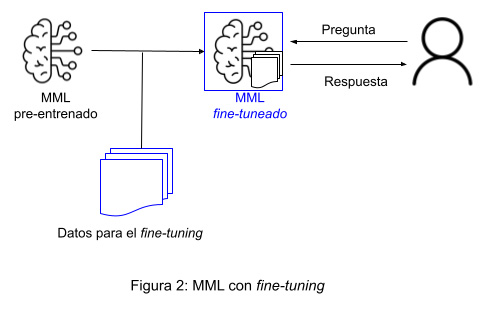
Por el contrario, el fine-tuning es una aproximación más específica en la que el modelo se entrena utilizando un conjunto de datos muy concretos y enfocados al caso de uso. Es la mejor opción cuando la tarea en cuestión exige un resultado muy particular (por ejemplo a nivel de estructura formal), un conocimiento profundo del dominio o una adaptación a una industria concreta. Esta técnica requiere de con conjuntos de datos de un cierto volumen para asegurar variedad y, por tanto, evitarla sobreadaptación del modelo (en inglés, over-fitting), que ocurre cuando este aprende de manera tan fiel los patrones que existen en los datos de entrenamiento, que es incapaz de generalizar y por tanto falla con datos nuevos que no ha visto y que son diferentes de los aprendidos.
La siguiente tabla detalla las diferencias principales entre estos dos enfoques:
| Prompting | Fine-tuning |
| Descripción general | |
| Se proporcionan instrucciones al modelo (posiblemente acompañadas de ejemplos) para guiar su comportamiento sin modificar significativamente su conocimiento previo. | Se instruye el modelo utilizando un conjunto de datos de cierto volumen, adaptándolo así a un contexto o tarea más especializada. |
| Flexibilidad | |
| Aproximación flexible y generalista, adecuada para una amplia gama de tareas. | Permite una adaptación más personalizada y específica a la labor; se sacrifica un cierto grado de capacidad generalista del modelo a cambio de mejorar su rendimiento en contextos específicos. |
| Complejidad | |
| Nivel de complejidad bajo en tanto que implica trabajar con las capacidades ya existentes del modelo pre-entrenado. | Nivel de complejidad mayor porque requiere la creación y gestión de un conjunto de datos especializado para el caso de uso. |
Aplicación de ejemplo
Analizaremos las implicaciones que tiene utilizar cada una de estas dos técnicas tomando como caso de uso un proyecto de implementación de una interfaz de lenguaje natural que permite interactuar con aplicaciones móviles simplemente pasando órdenes de voz. Se trata de un proyecto que no busca sólo mejorar el grado de usabilidad de las aplicaciones, sino contribuir hacia la inclusividad y la accesibilidad tecnológica para todos.
Una interfaz lingüística de este tipo incluye, a grandes rasgos, una herramienta de conversión de voz a texto y un componente de comprensión del lenguaje natural (CLN). Este componente CLN es la parte mágica que interpreta las intenciones de los usuarios y las convierte en una representación estructurada, lista para ser ejecutada por el componente backend de la aplicación.
Pero, ¿cómo funciona todo esto?
Explotando el potencial de los MML
Para que nuestro componente CLN sea inteligente y adaptable, recurrimos a un MML Aquí es donde está la verdadera magia. Un modelo bien aterrizado en las especificidades de la tarea será capaz de transformar la forma en que los usuarios interactúan con sus aplicaciones móviles. Pero para poder aterrizar, o personalizar, un MML de forma exitosa es necesario un proceso que pasa por diversas fases, tal y como se ilustra en la siguiente figura: análisis de la tarea, creación de los datos para instruir el modelo (ya sea vía prompting o fine-tuning) y, finalmente, implementación del modelo aterrizado. Dejaremos este último paso para una próxima publicación (por lo tanto, ¡estad atentos!) y nos centraremos en los dos primeros.
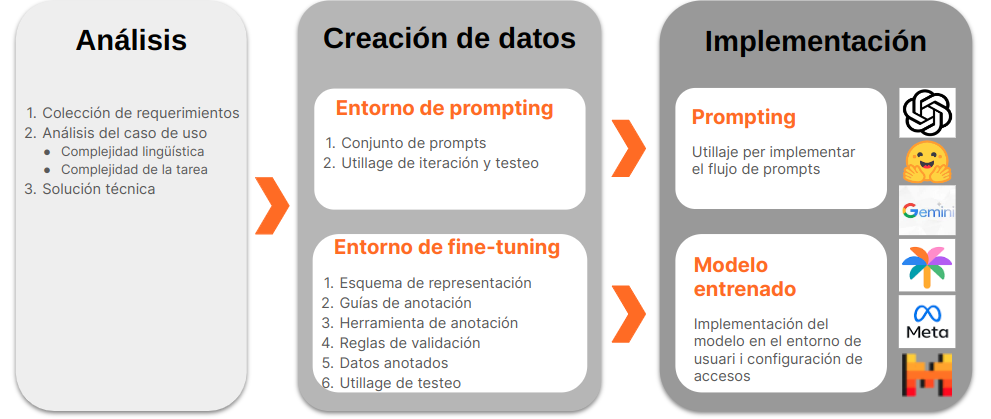
Paso 1. Análisis de la tarea
En primer lugar es imprescindible analizar de forma exhaustiva las especificidades de la tarea que el modelo debe aprender. Concretamente, es necesario entender las complejidades lingüísticas y de dominio que comporta.
Complejidad lingüística. Conviene tener en cuenta los idiomas a incluir en el proyecto. ¿Son lenguas con una gran cobertura digital y, por tanto, podemos asumir que ya están ampliamente representadas en el MML de base? También: ¿son lenguas similares y, por tanto, podemos pensar en la posibilidad de compartir los mismos datos a la hora de aterrizar el modelo?
Complejidad del dominio. También es necesario analizar la dificultad de la tarea a entrenar. ¿Cuál debe ser el nivel de complejidad de los datos de entrenamiento? ¿Cómo podemos estructurarlos para que el backend de la aplicación pueda ejecutarse correctamente? Para nuestro ejemplo de interfaz de accesibilidad, esto implicaría determinar los distintos intents (o intenciones) de usuario que queremos cubrir, sus parámetros y cualquier otro aspecto relacionado. Por ejemplo, sería relevante aquí pensar si es suficiente con establecer un único intent para calendarizar un evento o, por el contrario, hay que diferenciar entre dos en función de si se invita a otras personas o no. Igualmente, convendría determinar los elementos a distinguir en un intent de calendarización de eventos (p.ej., organizador, asistentes, fecha y hora, duración, ubicación, título), etc.
Este análisis ayuda a diseñar el proceso de aterrizaje del modelo y guía la elección de la solución tecnológica más adecuada: prompting, fine-tuning o una opción híbrida que combine ambas técnicas.
Imaginemos que en el caso de uso que nos ocupa existen dos funcionalidades que queremos desarrollar. Por un lado, nos interesa tener un paso que se encargue de procesar texto complejo (esto es, que incluye varios intents), como:
Responde el último mensaje de whatsapp de Maria con un pulgar de ok, reenvíalo al chat del equipo y después empieza a reproducir el vídeo que he recibido de Pau
y lo divida en instrucciones independientes; p.ej., de forma esquemática:1. responder al mensaje; 2, reenviarlo; 3. reproducir el vídeo. Por otro lado, queremos que el MML aprenda a interpretar pedidos de usuario, que pueden ser de tipo muy diverso, y que los represente según el esquema que requiere el backend.
La solución tecnológica que elegiremos es clara: mientras que la primera funcionalidad se puede entrenar simplemente con prompting, la segunda implica un grado de complejidad que sólo se puede gestionar recurriendo al fine-tuning (en la sección siguiente justificaremos el porqué con más detalle). Optamos pues por un enfoque híbrido que combina ambas técnicas.
2. Desarrollo de los datos
Una vez analizada la tarea y determinado el enfoque tecnológico a seguir, el siguiente paso es desarrollar de manera eficaz los recursos necesarios que nos permitirán personalizar el modelo.
Ecosistema de prompting
El prompting es un proceso de ensayo y error que se basa en un conjunto de instrucciones (llamado prompt) para instruir el modelo.Opcionalmente, también puede añadir ejemplos de entrada y salida de lo que espera. La figura 5 lo ilustra con un ejemplo muy sencillo para instruir al modelo a convertir órdenes de calendarización de eventos en estructuras JSON.
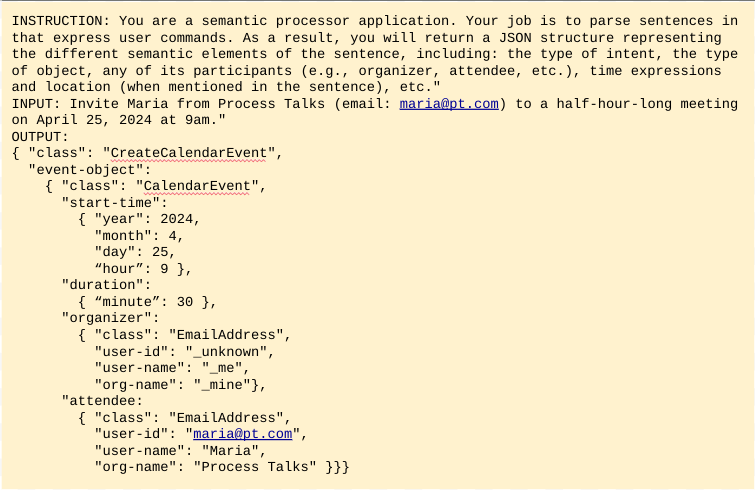
El entorno de desarrollo para la ingeniería de prompts es bastante sencillo, pues. Pide un conjunto de scripts (o elementos cortos de software) para iterar de forma rápida sobre diferentes versiones del prompt y realizar el testeo del resultado en cada iteración, una posibilidad que está al alcance de muchas empresas, incluidas aquellas con recursos técnicos limitados.
Sin embargo, como ya se ha mencionado, el prompting no es la solución indicada para tareas con un nivel significativo de complejidad. Concretamente, en tareas de generación de anotación o estructuras JSON, como en el ejemplo anterior, es muy probable que el resultado no valide respecto del esquema de representación. El modelo puede actuar de forma creativa devolviendo resultados no deseados, como la introducción de atributos inventados, una reestructuración de la jerarquía o la omisión de valores obligatorios. El prompting no es pues la mejor opción para nuestra tarea de CNL, aunque puede utilizarse para funciones más simples, como identificar y separar los varios intents que puede haber en una misma frase – como en el ejemplo de antes: Responde el último mensaje de whatsapp de Maria con un pulgar de ok, reenvíalo al chat del equipo y después empieza a reproducir el vídeo que he recibido de Pau.
Ajuste del ecosistema de datos
Los requisitos de entorno técnico son más exigentes en el caso del fine-tuning, que se emplea para aterrizar los MML en casos de usos complejos y, por tanto, necesita datos mucho más sofisticados. Para nuestra interfaz CLN, los datos que necesitamos son frases que expresen posibles órdenes de usuario acompañados de sus anotaciones; es decir, de sus representaciones estructuradas. Estas anotaciones deben satisfacer un cierto grado de calidad y coherencia para garantizar el mínimo ruido posible durante el entrenamiento del modelo, lo que exige intervención humana en distintos puntos del proceso de creación y curación de los datos.
Elementos clave para alcanzar el grado necesario de calidad y coherencia son:
- Un esquema de representación de datos que estructure el conjunto de intents posibles y sus parámetros. Este paso se da siempre en colaboración estrecha con el cliente o usuario – aquí, el propietario del componente backend que consumirá las representaciones resultantes.
Por ejemplo, el esquema para el intent de calendarizar un evento definirá los elementos que le son relevantes (Figura 6): hora de inicio, duración, ubicación, organizador, asistentes, etc. A su vez, cada uno de estos elementos se definirá con un esquema adicional al nivel de detalle necesario. Por ejemplo, los atributos organizador y asistente de la figura 6 serán configurados en el esquema del elemento usuario, que establece campos para el nombre, la dirección de correo electrónico, la empresa, etc. (Figura 7).


- Guías de anotación que aseguren que los anotadores expertos siguen unos mismos criterios de anotación y por tanto se garantice un nivel máximo de coherencia en los datos anotados. De no ser así, obtendremos datos ruidosos que perjudicarán la consistencia (y por tanto, el rendimiento) del MML. Las guías de anotación pueden incluir tanto indicaciones basadas en criterios lingüísticos, como por ejemplo las siguientes (en inglés), que dan instrucciones sobre cuándo anotar el usuario como organizador de un evento:

así como indicaciones basadas en conocimiento del mundo:

- Una herramienta de anotación que facilite la labor del anotador experto semi-automatizando algunos de los pasos de anotación, y que idealmente disponga también de mecanismos para garantizar la coherencia y la solidez de los datos.
En Process Talks hemos desarrollado nuestra propia herramienta, llamada WILMA, que entre otras funciones valida la estructura y la consistencia semántica de los datos anotados utilizando un conjunto de reglas de validación. La figura 10 muestra una de ellas, la cual exige que el intent de calendarizar eventos tenga siempre un organizador de una clase determinada (p. ej., que sea un usuario de Teams, una dirección de correo electrónico, etc.)

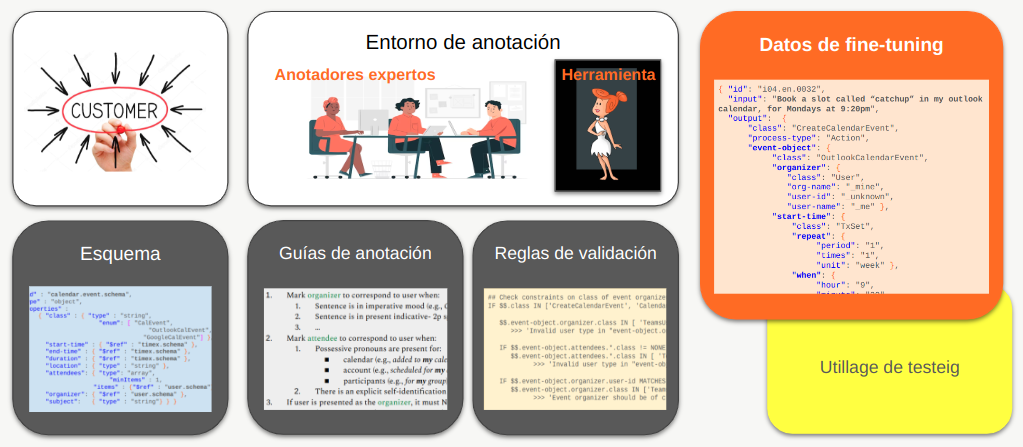
En resumen, la generación de datos de fine-tuning exige un ecosistema complejo (Figura 11). Componentes clave dentro de éste son, en primer lugar, la interacción con el cliente, que es el ingrediente imprescindible para definir el esquema a la base de los datos; en segundo lugar, una buena herramienta de anotación (como por ejemplo WILMA) que asegure un proceso de creación de datos lo más rápido y fluido posible; y finalmente, la intervención de anotadores expertos en distintos puntos del proceso, crucial para garantizar un nivel de calidad máxima de los datos.
Conclusión
Personalizar MMLs para casos complejos puede ser una tarea tediosa y compleja, pero con una buena orientación el resultado aportará mejoras remarcables a sus proyectos. En Process Talks estamos especializados en aterrizar modelos de este tipo y ofrecemos soluciones a medida. Contáctenos y analizaremos con usted cómo podemos ayudarle a hacer crecer sus proyectos y llevarlos a nuevos niveles de funcionalidad gracias al enorme potencial de la IA generativa.





