
El camp de la Intel·ligència Artificial (IA) ha estat testimoni aquest darrer any d’un augment sense precedents en l’ús de la IA generativa gràcies a l’adopció generalitzada de models massius de llenguatge (MML) per a una infinitat de tasques. Des de funcions de resum automàtic o reescriptura de text fins a tasques més complexes, els MML s’han convertit en la solució ideal per a reptes de caire molt divers.
Tanmateix, per tal d’aprofitar-ne realment tot el seu poder, molt sovint cal el que tècnicament es coneix com “fer aterrar” aquests models; és a dir, personalitzar-los per què satisfacin els requisits específics de cada cas. Algunes tècniques per fer-ho són les que es coneixen amb els termes anglesos de prompting, fine-tuning i retrieval augmented generation (RAG). Les tècniques de prompting i fine-tuning difereixen de RAG perquè impliquen instruir el model en el «com» (és a dir, en com realitzar millor una tasca), mentre que RAG l’instrueix en el «què» (què ha de saber el model per entendre i resoldre qüestions sobre un domini determinat). En aquest article, ens centrarem en les dues primeres tècniques, explicant oom les podeu incorporar en els vostres projectes per elevar-los a nivells superiors de qualitat, rendiment i usabilitat.
Prompting vs. Fine-tuning
El prompting consisteix en guiar el comportament del model proporcionant-li instruccions (possiblement acompanyades d’exemples) que indiquen el tipus de resultat que s’espera. És ideal quan la tasca a realitzar permet una aproximació general i no hi ha necessitat d’aprofundir en detalls gaire específics o tècnics.
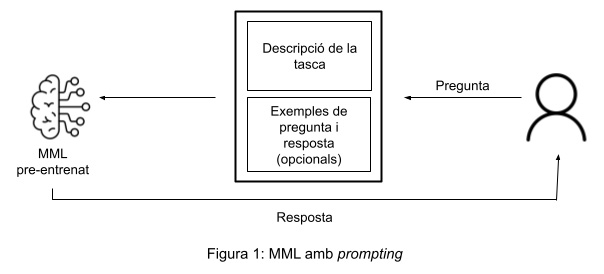
Per contra, el fine-tuning és una aproximació més específica on el model s’entrena fent servir un conjunt de dades molt concret i enfocat al cas d’ús. És la millor opció quan la tasca en qüestió exigeix un resultat molt particular (per exemple a nivell d’estructura formal), un coneixement profund del domini o bé una adaptació a una indústria concreta. Aquesta tècnica demana treballar amb conjunts de dades d’un cert volum per tal d’assegurar varietat i, per tant, evitarla sobreadaptació del model (en anglès, over-fitting), que passa quan el model aprèn de manera tan fidel els patrons que hi ha en les dades d’entrenament, que és incapaç de generalitzar i per tant falla amb dades noves que no ha vist i que són diferents de les apreses.
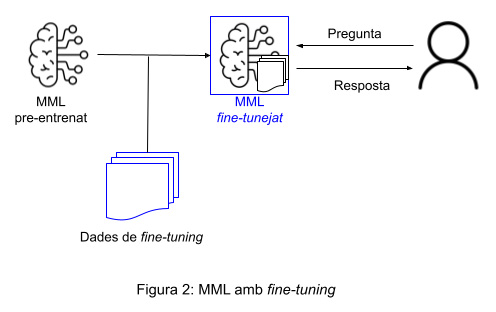
La taula següent detalla les diferències entre aquests dos enfocs:
| Prompting | Fine-tuning |
| Descripció general | |
| Es proporcionen instruccions al model (possiblement acompanyades d’exemples) per guiar-ne el seu comportament sense modificar-ne significativament el seu coneixement previ. | S’instrueix el model fent servir un conjunt de dades d’un cert volum, adaptant-lo així a un context o tasca més especialitzada. |
| Flexibilitat | |
| Aproximació flexible i generalista, adequada per a una gamma de tasques àmplia. | Permet una adaptació més personalitzada i específica a la tasca; se sacrifica un cert grau de capacitat generalista del model a canvi de millorar-ne el rendiment en contextos específics. |
| Complexitat | |
| Nivell de complexitat baix en tant que implica treballar amb les capacitats ja existents del model pre-entrenat. | Nivell de complexitat més alt perquè requereix la creació i gestió d’un conjunt de dades especialitzat per al cas d’ús. |
Aplicació d’exemple
Analitzarem les implicacions que té utilitzar cada una d’aquestes dues tècniques prenent com a cas d’ús un projecte d’implementació d’una interfície de llenguatge natural que permet interactuar amb aplicacions mòbils simplement passant ordres de veu. Es tracta d’un projecte que no busca només millorar el grau d’usabilitat de les aplicacions, sinó de contribuir cap a la inclusivitat i l’accessibilitat tecnològica per a tothom.
Una interfície lingüística d’aquest tipus inclou, a grans trets, una eina de conversió de veu a text i un component de comprensió del llenguatge natural (CLN). Aquest component CLN és la part màgica que interpreta les intencions dels usuaris i les tradueix en una representació ben estructurada, llesta per ser executada pel component al backend de l’aplicació. Però, com funciona tot això?
Explotant el potencial dels MML
Per fer que el nostre component CLN sigui intel·ligent i adaptable, recorrem a un MML. Aquí és on hi ha la veritable màgia. Un model ben aterrat a les especificitats de la tasca serà capaç de transformar la manera com els usuaris interactuen amb les aplicacions mòbils. Però per poder aterrar, o personalitzar, un MML de manera exitosa cal un procés que passa per diverses fases, tal i com s’il·lustra a la següent figura: anàlisi de la tasca, creació de les dades per instruir el model (ja sigui via prompting o fine-tuning) i, finalment, implementació del model aterrat. Deixarem aquest darrer pas per a una propera publicació (per tant, estigueu atents!) i ens centrarem en els dos primers.
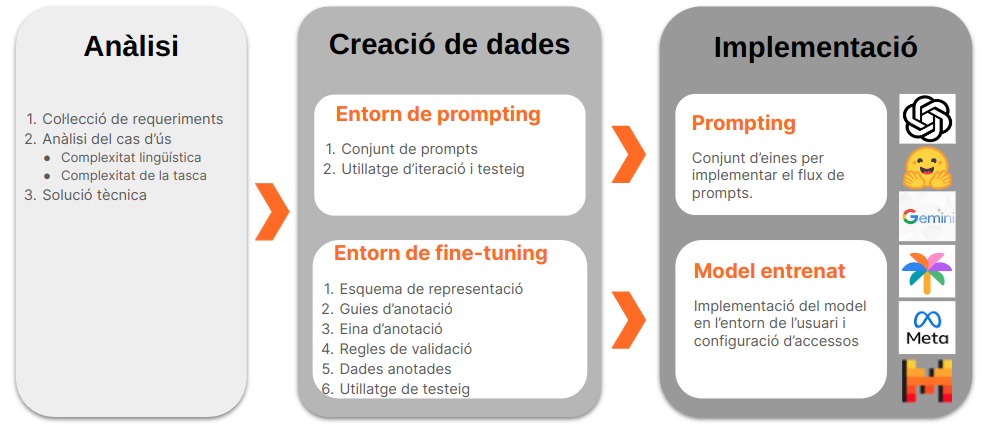
Pas 1. Anàlisi de la tasca
En primer lloc és imprescindible analitzar de manera exhaustiva les especificitats de la tasca que el model ha d’aprendre. Concretament, cal entendre’n les complexitats lingüístiques i de domini que comporta.
Complexitat lingüística. Convé tenir en compte els idiomes a incloure al projecte. Són llengües amb una gran cobertura digital i, per tant, podem assumir que ja estan àmpliament representades a l’MML de base? També: són llengües semblants i, per tant, podem pensar en la possibilitat de compartir les mateixes dades a l’hora d’aterrar el model?
Complexitat del domini. També cal analitzar la dificultat de la tasca a entrenar. Quin ha de ser el nivell de complexitat de les dades d’entrenament? Com podem estructurar-les per tal que el backend de l’aplicació pugui executar-se correctament? Per al nostre exemple d’interfície d’accessibilitat, això implicaria determinar els diferents intents (o intencions) d’usuari que volem cobrir, els seus paràmetres i qualsevol altre aspecte relacionat. Per exemple, seria rellevant aquí pensar si n’hi ha prou amb establir un únic intent per calendaritzar un esdeveniment o, per contra, cal diferenciar-ne dos en funció de si es convida a altres persones o no. Igualment, convindria determinar els elements que cal distingir en un intent de calendarització d’esdeveniments (p.ex., organitzador, assistents, data i hora, durada, ubicació, títol), etc.
Aquesta anàlisi ajuda a dissenyar el procés d’aterratge del model i guia l’elecció de la solució tecnològica més adequada: prompting, fine-tuning o una opció híbrida que combini totes dues tècniques.
Imaginem que en el cas d’ús que ens ocupa hi ha dues funcionalitats que volem desenvolupar. D’una banda, ens interessa tenir un pas que s’encarregui de processar text complex (és a dir, que inclou diversos intents), com en:
Respon l’últim missatge de whatsapp de la Maria amb un polze d’ok, reenvia’l al xat de l’equip i després comença a reproduir el vídeo que he rebut d’en Pau
i el divideixi en comandes independents; p.ex., de manera esquemàtica: 1. respondre el missatge; 2, reenviar-lo; 3. reproduir el vídeo. D’altra banda, volem que el MML aprengui a interpretar comandes d’usuari, les quals poden ser de tipus molt divers, i que les representi segons l’esquema que requereix el backend.
La solució tecnològica a la que optarem per aterrar el model és clara: mentre que la primera funcionalitat es pot entrenar simplement amb prompting, la segona implica un grau de complexitat que només es pot gestionar recorrent al fine-tuning (a la secció següent justificarem el perquè amb més detall). Optem doncs per un enfocament híbrid que combina totes dues tècniques.
2. Desenvolupament de les dades
Un cop analitzada la tasca i determinat l’enfoc tecnològic a seguir, el pas següent és desenvolupar de manera eficaç els recursos necessaris que ens permetran de personalitzar el model.
Ecosistema de prompting
El prompting és un procés d’assaig i error que es basa en un conjunt d’instruccions (anomenat prompt) per instruir el model. Opcionalment, també pot afegir exemples d’entrada i sortida del que s’espera. La figura 5 ho il·lustra amb un exemple molt senzill per ensenyar el model a convertir comandes de calendarització esdeveniments en estructures JSON.
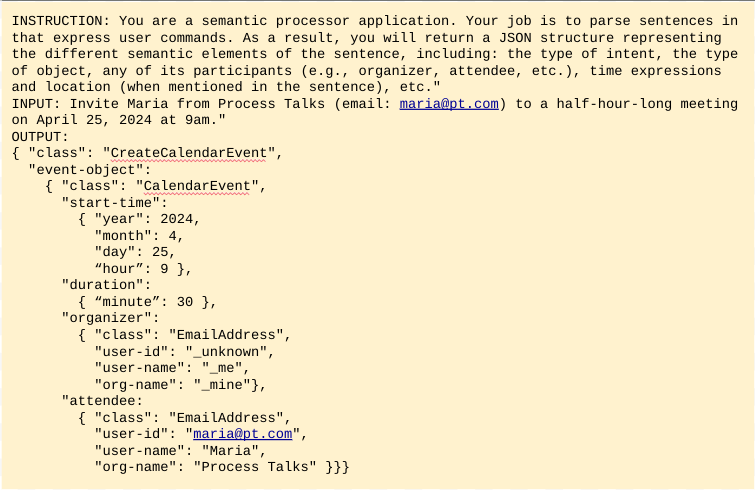
L’entorn de desenvolupament per a l’enginyeria de prompts és força senzill, doncs. Demana un conjunt d’scripts (o peces curtes de programari) per iterar de manera ràpida sobre diferents versions del prompt i fer el testeig del resultat a cada iteració, una possibilitat que està a l’abast de moltes empreses, incloses aquelles amb recursos tècnics limitats.
Com ja s’ha esmentat, però, el prompting no és la solució indicada per a tasques amb un nivell significatiu de complexitat. Concretament, si s’ha de generar estructures JSON com en l’exemple anterior, és molt probable que el resultat no validi respecte de l’esquema de representació. El model pot actuar de manera creativa retornant resultats no desitjats, com ara la introducció d’atributs inventats, una reestructuració de la jerarquia o l’omissió de valors obligatoris. Prompting no és doncs la millor opció per a la nostra tasca de CNL, tot i que es pot utilitzar per a d’altres més simples, com ara identificar i separar els diversos intents que hi pot haver en una única frase – com en l’exemple d’abans: Respon l’últim missatge de whatsapp de la Maria amb un polze d’ok, reenvia’l al xat de l’equip i després comença a reproduir el vídeo que he rebut d’en Pau.
Ecosistema de fine-tuning
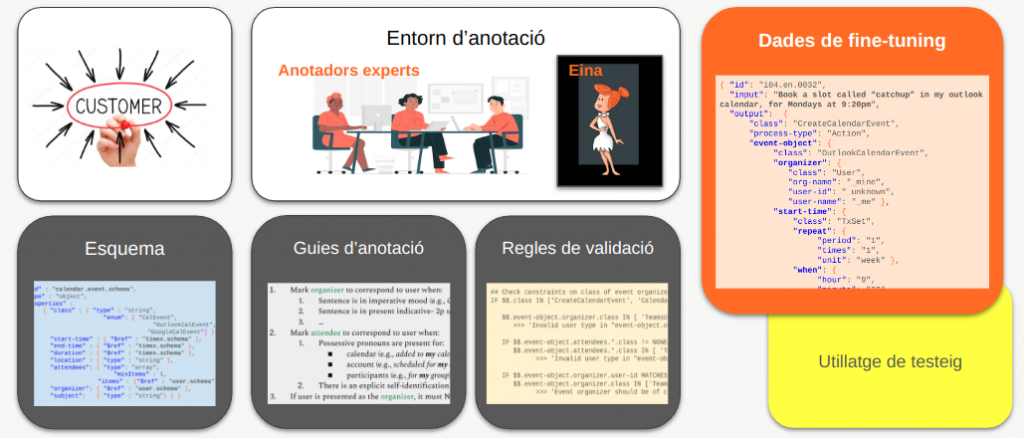
Els requisits d’entorn tècnic són més exigents en el cas del fine-tuning, que s’empra per aterrar els MML en casos d’usos complexos i, per tant, necessita dades molt més sofisticades. Per a la nostra interfície CLN, les dades que necessitaríem són frases que expressin possibles comandes d’usuari acompanyades de les seves anotacions; és a dir, de les seves representacions estructurades. Aquestes anotacions han de satisfer un cert grau de qualitat i coherència per tal de garantir el mínim soroll possible durant l’entrenament del model, fet que exigeix intervenció humana en diferents punts del procés de creació i curació de les dades.
Elements clau per assolir el grau necessari de qualitat i coherència són:
- Un esquema de representació de dades que estructuri el conjunt d’intents possibles i els seus paràmetres. Aquest pas es fa sempre en col·laboració estreta amb el client o usuari – aquí, el propietari del component backend que consumirà les representacions resultants.
Per exemple, l’esquema per a l’intent de calendaritzar un esdeveniment definirà els elements que li són rellevants (Figura 6): hora d’inici, durada, ubicació, organitzador, assistents, etc. Al seu torn, cadascun d’aquests elements es definirà amb un esquema addicional al nivell de detall necessari. Per exemple, els atributs organitzador i assistent de la figura 6 seran per exemple configurats a l’esquema de l’element usuari, que estableix camps per al nom, l’adreça de correu electrònic, l’empresa, etc. (Figura 7).


- Guies d’anotació que assegurin que els anotadors experts segueixen uns mateixos criteris d’anotació i per tant es garanteixi un nivell màxim de coherència en les dades anotades. De no ser així, obtindrem dades sorolloses que perjudicaran la consistència (i per tant, el rendiment) de l’MML. Les guies d’anotació poden incloure tant indicacions basades en criteris lingüístics, com per exemple les següents (en anglès), que donen instruccions sobre quan anotar l’usuari com a organitzador d’un esdeveniment:


- Una eina d’anotació que faciliti la tasca de l’anotador expert semi-automatitzant alguns dels passos d’anotació, i que idealment disposi també de mecanismes per garantir la coherència i la solidesa de les dades.
A Process Talks hem desenvolupat la nostra pròpia eina, anomenada WILMA, que entre altres funcions valida l’estructura i la consistència semàntica de les dades anotades, fent servir un conjunt de regles de validació. La figura 10 en mostra una, que exigeix que l’intent de calendaritzar esdeveniments tingui sempre un organitzador d’una classe determinada (p. ex., que sigui un usuari de Teams, una adreça de correu electrònic, etc.)

En resum, la generació de dades de fine-tuning exigeix un ecosistema complex (Figura 11). Components clau dins d’aquest són, en primer lloc, la interacció amb el client, que és l’ingredient imprescindible per definir l’esquema a la base de les dades; en segon lloc, una bona eina d’anotació (com per exemple WILMA) que asseguri un procés de creació de dades el més ràpid i fluid possible; i finalment, la intervenció d’anotadors experts en diferents punts del procés, crucial per garantir un nivell de qualitat màxima de les dades.
Conclusió
Personalitzar MMLs per a casos complexos pot ser una tasca tediosa i complexa, però amb una bona orientació el resultat aportarà millores remarcables als vostres projectes. A Process Talks estem especialitzats en fer aterrar models d’aquest tipus i oferim solucions a mida. Contacteu-nos i analitzarem amb vosaltres com us podem ajudar a fer créixer els vostres projectes i portar-los a nous nivells de funcionalitat gràcies a l’enorme potencial de la IA generativa.





